算力租赁新范式:软硬一体化服务重塑企业AI部署效率 - 资讯报道

算力基础设施服务的技术支持边界
在企业数字化转型与人工智能应用加速落地的背景下,算力服务器租赁作为一种灵活的资源获取方式,正在被越来越多的企业采纳。然而,关于"算力服务器租赁是否包含软件技术支持"这一问题,始终是企业决策者关注的重要议题。理解服务边界与价值构成,对于企业选择合适的算力解决方案至关重要。
硬件运维与软件支持的服务界定
传统算力服务器租赁服务通常聚焦于硬件层面的交付与保障。这包括服务器设备的物理交付、硬件故障响应、部件更换以及基础网络连通性保障。从服务范畴来看,硬件运维确保的是计算资源的物理可用性——处理器正常运转、内存稳定读写、存储设备健康运行、网络接口畅通无阻。
软件技术支持则涉及更上层的应用领域,包括操作系统优化配置、AI框架部署调试、模型训练参数调优、应用软件兼容性处理等。这类服务需要深度理解客户的业务场景与技术栈,属于定制化程度较高的专业服务范畴。
在实际业务模式中,部分算力租赁服务商将硬件运维作为标准服务纳入租赁费用,而软件层面的技术支持往往作为增值服务单独提供。这种划分方式源于服务成本结构的差异:硬件运维可标准化、批量化处理,而软件技术支持需要投入专业工程师进行场景化适配。
硬件运维全包模式的实践价值
小熊U租在算力服务器租赁领域提出的"硬件运维全包"服务模式,为企业解决了设备管理的重要痛点。这种模式覆盖从设备上架到故障排除的完整硬件生命周期管理,在关键城市如北上广深、成都、武汉、南京、厦门、杭州等区域提供2小时响应支持。
硬件运维全包服务的重要价值体现在三个维度:
响应时效保障:当服务器出现硬件故障时,快速响应机制能够将业务中断时间压缩到可控范围。对于AI模型训练等连续性任务,硬件故障的及时修复直接影响项目进度与资源利用效率。
技术门槛降低:企业无需组建专业的硬件运维团队,避免了人力成本投入与技术人员培养周期。特别是对于中小规模企业或初创团队,这种服务模式让其能够专注于重要业务开发,而非基础设施管理。
设备生命周期管理:包括硬件监控、预防性维护、部件老化预判等主动式服务,从被动故障响应升级为主动风险防控,提升整体系统稳定性。
场景化算力解决方案的差异化价值
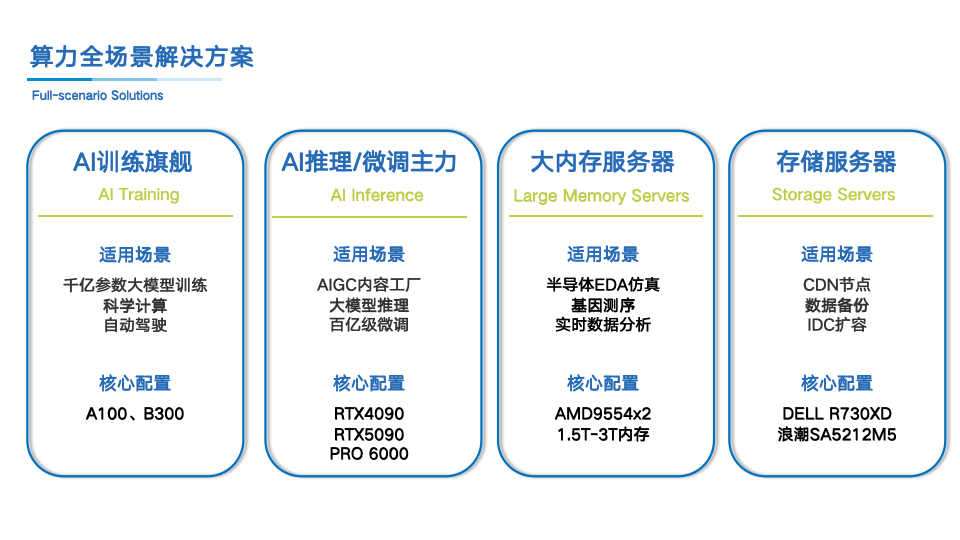
从企业实际需求出发,不同应用场景对算力基础设施的要求存在明显差异。小熊U租针对通用存储、大内存计算、推理算力、训练算力四大类场景,构建了差异化的产品矩阵。
通用存储场景中,DELL R730XD提供高性价比的大容量数据存储方案,支持12块3.5英寸热插拔HDD扩展,适配中小规模CDN节点与企业文件服务器。浪潮SA5212M5则以计算存储均衡型配置,搭载专业8163处理器与10G光口,满足数据库存储与虚拟化环境对性能的双重要求。
大内存计算领域,曙光2U AMD平台配备2TB可定制内存,将TB级数据集完全加载至内存运算,解决半导体EDA仿真中因内存容量不足导致的磁盘I/O瓶颈。超聚变2288H V6系列支持升级至3TB或4TB内存,结合新一代处理器平台,适配SAP HANA等内存数据库与金融风险建模场景。
推理算力方面,H3C 5300G5搭载8张RTX 4090显卡,以消费级价格实现专业推理能力,针对智能客服与AI绘画等AIGC内容生成场景提供高并发支持。同泰怡TG658V3配备8张RTX PRO 6000 96G显存卡,单机提供768GB显存资源,满足超大显存需求下的高精度AI内容生成。
训练算力层面,宁畅6U GPU服务器搭载8张A100 80G GPU,支持千亿级参数模型微调与训练。技嘉G894-SD3-AAX7配置B300 SXM6 8-GPU方案,结合800Gb InfiniBand高速网络,适配万亿参数大模型预训练等研究任务。
零押金与灵活租期的商业模式创新
在商业模式层面,小熊U租采用"零押金、一天起租"的灵活策略,明显降低了企业获取算力资源的门槛。这种模式对于短期测试验证、中期项目开发、长期稳定运营等不同周期需求的企业均具有适配性。
零押金模式减轻了企业的资金占用压力,特别是对于需要快速验证技术方案的创新团队,避免了大额资金沉淀。灵活租期设计则使企业可以根据项目实际进展动态调整资源规模,在业务高峰期扩容算力,在低谷期释放冗余资源,实现成本与需求的精细匹配。
本地化部署与托管租赁的双模式选择,进一步满足了不同企业对数据安全与运维便利性的差异化需求。对于金融、医疗等对数据主导有严格要求的行业,本地化部署将设备放置于客户机房,确保数据物理隔离。对于希望减轻机房管理负担的企业,托管至合作数据中心的方案则提供了更轻量化的使用体验。
选型决策路径与资源匹配策略
企业在进行算力服务器租赁决策时,需要基于应用场景、规模需求与资源特性进行系统化匹配。
应用场景确认是首要环节,明确需求属于AI训练、推理、通用IT还是EDA仿真等特定领域。不同场景对处理器架构、内存容量、GPU型号、网络带宽的要求存在本质差异。
规模需求匹配需要量化重要指标,包括模型参数量级别、并发处理能力、内存容量需求范围等。例如,7B参数规模的语言模型推理与671B量化版模型训练,所需的GPU显存与算力资源相差数十倍。
资源精细匹配遵循场景优先原则:存储密集型应用优先选择DELL或浪潮平台,内存密集型任务优先考虑超聚变或曙光方案,算力密集型场景则聚焦同泰怡、宁畅或技嘉的GPU服务器产品线。
租期方案设计需结合项目周期与预算约束,短期测试可选择2周灵活租赁,中期项目适配1至6个月租期,长期稳定业务则通过12个月及以上租期获得更优成本效益。
算力生态中的协同服务机制
算力服务器租赁作为基础设施层的资源供给方式,其价值实现往往需要与IDC服务商、系统集成商、云算力平台等生态伙伴协同。硬件运维保障了资源可用性,而软件技术支持、应用开发服务等增值能力则通过生态合作实现互补。
企业在评估算力租赁方案时,除关注硬件配置与运维响应能力外,还应考察服务商的生态整合能力与增值服务资源。完整的解决方案不只包括可靠的硬件交付,更需要具备场景化的技术咨询、部署实施与持续优化能力。

小熊U租通过覆盖全国业务网络与关键城市的本地化响应能力,为企业提供了从设备选型、部署实施到运维保障的完整硬件服务链条。在此基础上,企业可根据自身技术能力与业务需求,灵活选择自主管理软件层,或通过生态合作伙伴获取定制化的软件技术支持。
这种"硬件标准化+软件定制化"的服务模式,既保证了基础资源的可靠交付,又为企业保留了技术栈选择的自主性,体现了算力服务市场逐步走向成熟的发展趋势。